오늘은 회사에서 진행한 업무중에 대량으로 사용자에게 이메일/문자를 전송하는 기능을 구현하는 과정에서 성능 테스트를 진행하고, 성능개선한 후기를 작성하려고합니다!
여려명의 사용자가 자신만의 고객을 만들 수 있는데 (설문조사 등을 통해) 이때 설문에 참여한 고객들에게 대량의 이메일/문자를 발송할 수 있는 기능 중 사용자를 여러명 선택후 예약된 시간에 이메일/문자를 발송하는 기능을 구현하는 과정에서, 너무나도 당연하게 사용자 수가 많아 질 수록 속도가 엄청 오래걸리는 문제가 발생했고, 이를 해결하는 것을 목표로 성능 개선에 집착했습니다!
그래서 선택한 기술은 ExecutorService를 사용해 속도를 개선했습니다.
먼저 시나리오는 다음과 같습니다.

하지만 테스트용도로 작성하는 점과 회사 코드이기 때문에 약소하게 테스트 환경을 구성했습니다.
Controller -> Service -> MessaeQueue Publishing
이렇게 진행하려고합니다.
먼저 Thread Pool에 대해 알아보려고 합니다.
Thread Pool
병렬 처리 작업이 많아지면 쓰레드가 계속 생성되고, 쓰레드가 생성되면 메모리 사용량이 계속 증가하게 됩니다. 이때 Thread는 스위칭 작업을 할 때 비용 및 시간이 발생하는데, 순차적으로 실행하는 것보다 더 오래걸릴 수 있습니다.
따라서 Thread를 잘못 사용하면 오히려 순차적으로 작업할 때 보다 성능이 더 안좋고 메모리도 오버 될 수있습니다.
따라서 미리 사용할 Thread를 정의하고 필요할 때 하나씩 할당하도록 도와주는 것이 ExecutorService입니다.

ExecutorService 클래스를 따라 올라가면 Executor를 상속받는 인터페이스임을 알수 있는데요. 이 클래스의 구현체는 여러개 있는데, 저는 newFixedThreadpool을 사용하기로 했습니다
그 이유는 다음과 같습니다.
- 작업이 규칙적이고 예측이 가능하기 때문
- 인스턴스 사양에 알맞게 배치를 돌리고싶기 때문 (비용 문제)
- 대량 건 수라도 소량으로 짤라서 전송하기 떄문
- 단순히 메시지 큐에 데이터를 전송하기 때문
- 메시지큐에 발행하는 배치, 큐를 소비하는 배치를 따로 작업해서 관리하기 때문
이러한 이유때문에 newFixedThreadPool를 사용하기로 했습니다.
먼저 성능을 알아보기 위해 Grafana Prometheus를 Docker-compose 파일로 작성했습니다.
version: '3'
services:
activemq:
image: rmohr/activemq:5.15.9
container_name: activemq
ports:
- "61616:61616"
- "8161:8161"
environment:
ACTIVEMQ_ADMIN_LOGIN: admin
ACTIVEMQ_ADMIN_PASSWORD: admin
ACTIVEMQ_CONFIG_MIN_MEMORY: 512
ACTIVEMQ_CONFIG_MAX_MEMORY: 2048
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- "9090:9090"
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
# 메모리 부족으로,, 몽고는 제 개인 서버에 올려서 썼습니다..
# mongo:
# image: mongo:4.4
# container_name: mongo
# environment:
# MONGO_INITDB_DATABASE: test # 생성할 데이터베이스 이름 지정
# ports:
# - "27017:27017"
# volumes:
# - ./init:/docker-entrypoint-initdb.d
# controller:
# image: ngrinder/controller:3.5.5
# restart: always
# ports:
# - "9000:80"
# - "16001:16001"
# - "12000-12009:12000-12009"
# volumes:
# - ./ngrinder-controller:/opt/ngrinder-controller
# agent:
# image: ngrinder/agent:3.5.5
# restart: always
# links:
# - controller
그리고 prometheus의 설정파일도 프로젝트 루트에 만든 다음에 아래 내용을 적어줍니다.
global:
scrape_interval: 15s
scrape_configs:
- job_name: prometheus
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['host.docker.internal:8080']
이떄 스프링 WAS는 localhost 이지만 prometheus를 docker로 띄웠기 떄문에 host.docker.internal로 작성해주셔야합니다.
프로메테우스랑 그라파나 초기 세팅은 생략하겠습니다
(dashboard 는 4701을 사용)
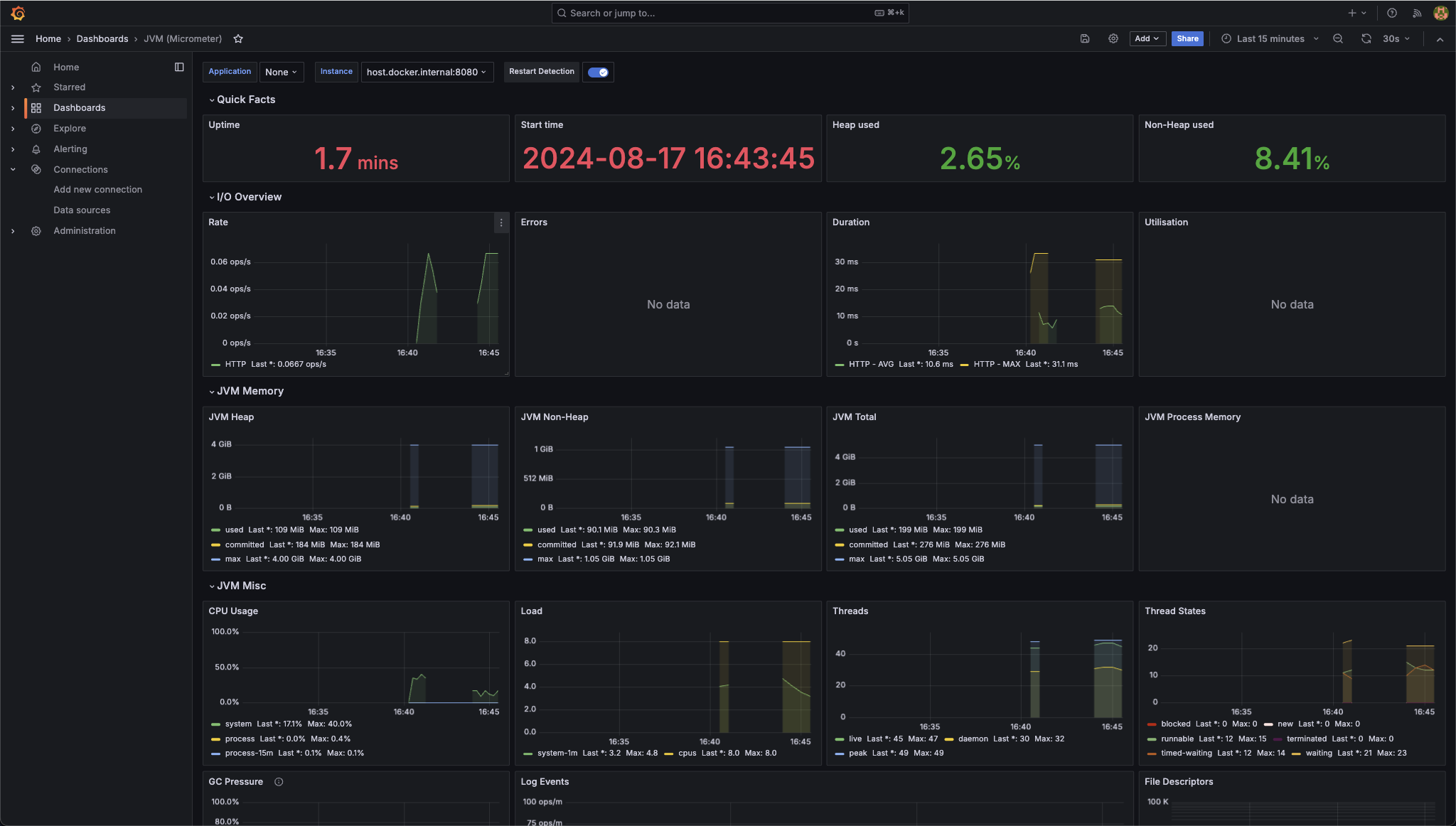
1. 1개의 쓰레드로 순차적으로 메시지 큐에 저장
먼저 첫번쨰로 아래 로직처럼 진행했을 때 어느정도 시간이걸리나 측정을 해봤습니다
public void sendEmailDefault() {
// 10000개씩 끊어서 저장
List<Member> memberList = memberRepository.findTop1000ByIsSend(false);
for(Member member : memberList) {
sendMessageQueue(member); // 이 메서드 내에 대기 시간이 포함될 가능성이 큼
}
}
응답 속도 - 3분 51초
속도는 굉장히 느리지만, CPU가 안정적인것을 확인할 수 있습니다. 하지만 속도가 느리다면 사용자 경험에 굉장히 부정적이고, 2시에 예약 이메일을 보냈지만 최악의 경우 몇시간 뒤에 받을 수도 있습니다.
따라서 해당 부분을 쓰레드를 이용해서 병렬처리 해야겠다고 생각이 들었습니다.
2. 16개의 쓰레드로 순차적으로 메시지 큐에 저장
public void sendEmailThread() throws InterruptedException {
// 10000개씩 끊어서 저장
List<Member> memberList = memberRepository.findTop1000ByIsSend(false);
int numThreads = 16; // 사용할 쓰레드 수
int batchSize = memberList.size() / numThreads; // 각 쓰레드가 처리할 작업 수
ExecutorService executorService = Executors.newFixedThreadPool(numThreads);
CountDownLatch latch = new CountDownLatch(numThreads);
for(int i = 0; i < numThreads; i++) {
int start = i * batchSize;
int end = (i == numThreads - 1) ? memberList.size() : (i + 1) * batchSize;
List<Member> subList = memberList.subList(start, end);
executorService.submit(() -> {
for(Member member : subList) {
sendMessageQueue(member);
}
latch.countDown();
});
}
// 모든 스레드가 완료될 때까지 대기
latch.await();
// ExecutorService 종료
executorService.shutdown();
System.out.println("service end");
}
먼저 해당 코드에서 16개를 사용한 이유는 현재 내 노트북이 MacBook Air M2 8코어 이기 때문에 내 코어수 * 2를 해서 나온 공식입니다.
원래는 코어수 * (1 + 대기시간 / 처리시간)을 계산해서 넣어야하지만, 대기시간 / 처리시간이 소수점으로 나왔기 떄문에, 8 * 2 를 진행해서 16개로 진행했습니다.
그리고 실제로는 배치로 작업을 돌리기때문에 1,000건씩 끊어서 메시지큐에 삽입을 진행했습니다. 배치인 이유도있고, 여러명의 유저가 대량의 이메일/문자를 발송할 수 있기 때문에 한명의 유저가 100만건을 보내게되면 100만건이 끝날때까지 그 뒤에 예약전송한 건은 한정적으로 대기상태에 걸리기 때문에 1000건씩 끊어서 처리하도록 진행했습니다.
추가로 배치 특성상 N분마다 실행되기때문에 실행중이라면 앞단에서 DB Lock을 걸어주어 동시성 문제를 해결해야 합니다.
하지만 본 예제에서는 한번만 요청하기때문에 Lock 은 생략했습니다.
초기에는 비동기로 돌리고 끝나면 괜찮겠다 싶어서 비동기로 처리했지만, 요청이 끊기니까 비동기도 어느정도 돌다가 끝까지 안돌더라고요..
그래서 CountDownLatch를 이용해서 await()를 이용해서 모든 쓰레드가 다 끝날때까지 기다려준 뒤 executorService를 종료시켰습니다.
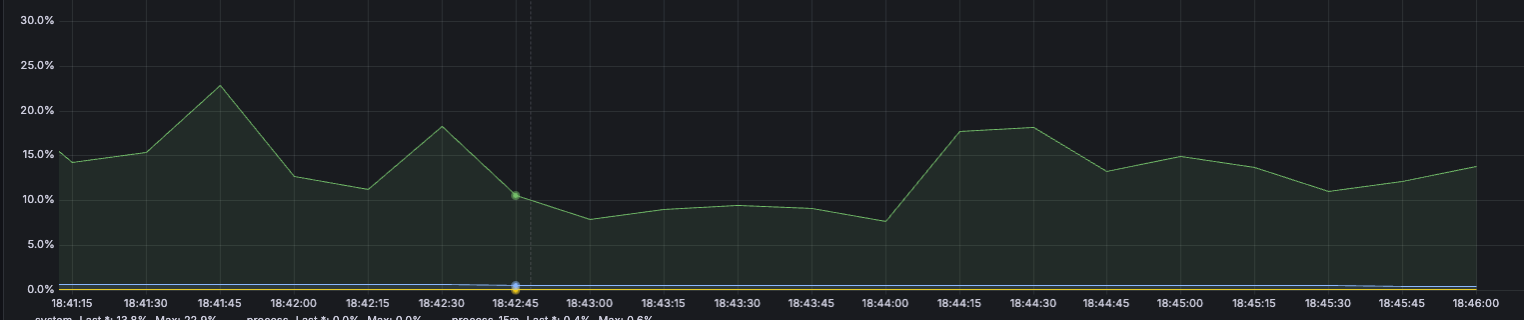
응답 속도 - 14초
CPU가 갑자기 확 튀었지만 응답 속도가 확연히 줄어든 것을 확인할 수 있습니다.
그렇다면! 쓰레드 수를 한번 조정해볼까? 라는 생각이 들었고, 조금 줄여 5개로 진행해봤습니다.
[실험] 5개의 쓰레드로 순차적으로 메시지 큐에 저장
응답 속도 - 52초
맨처음에 3분 50초에 걸린거에 비하면 많이 줄어들은 속도지만 50초도 상당히 긴 시간으로 느껴집니다.
cpu는 16개일때 보다 안정적이지만 속도는 늘어난 것을 확인했습니다.
그럼 Thread는 많을 수록 좋은거아니야?
이런 생각을 했습니다. 그래서 바로 실험을 진행하였고, Thread를 100개로 설정하고 테스트를 진행했습니다.
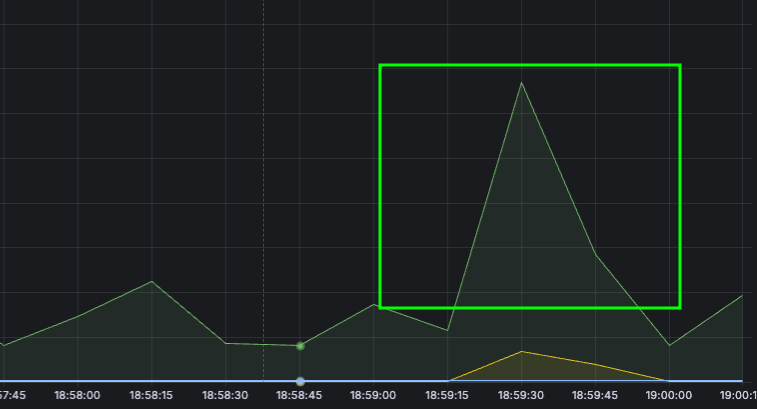
응답 속도 - 11초
오? 응답 속도가 줄어드네? 그렇다면 Thread를 1,000개로 설정하고 다시 테스트를 진행해봤습니다.
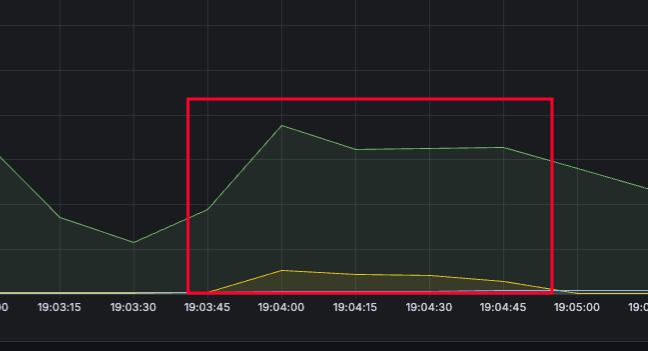
응답 속도 - 12초
100개였을 때보다 더 시간이 걸렸습니다.
이 문제가 궁금해서 찾아봤더니 컨텍스트 스위칭 오버헤드 문제가 발생하기 때문이였죠
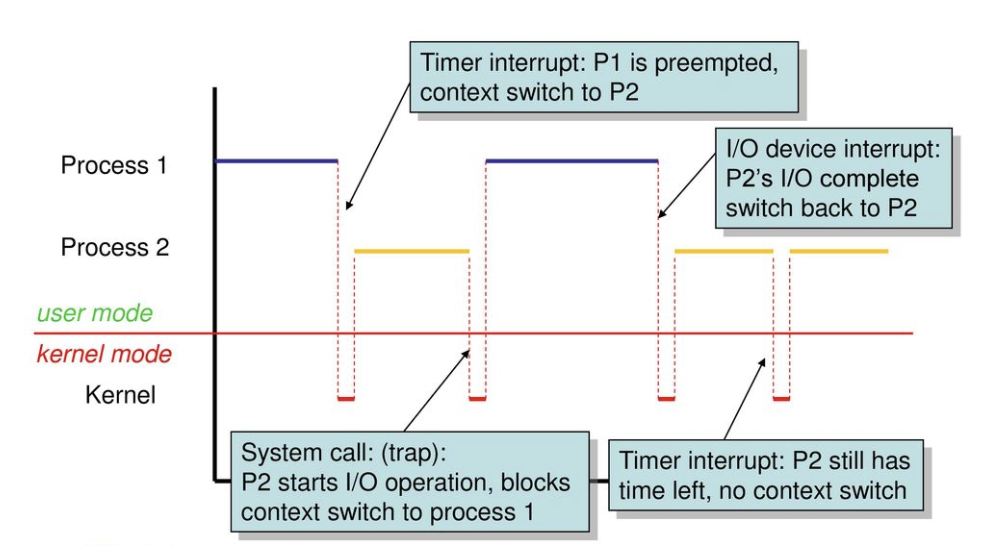
위 그림을 보면 쓰레드가 여러개일 때 CPU가 현재 스레드의 상태를 저장하고 다른 스레드로 전환하는 과정을 컨텍스트 스위칭인데, 이때 CPU시간과 자원을 소모하므로 오버헤드가 발생한다고 합니다!
따라서 단일 쓰레드에서는 컨텐스트 스위칭 오버헤드가 발생하지는 않지만 멀티스레드에서는 오버헤드가 발생해 성능이 저하될수 있습니다.
Thread를 무조건적으로 늘린다고 성능 개선되는 것이 아님을 알게 되었고, 적정 스레드를 사용해야 성능 개선에 이점이 있다는 점을 알게 되었습니다.
Git Code
https://github.com/Darren4641/PerformanceTest
GitHub - Darren4641/PerformanceTest
Contribute to Darren4641/PerformanceTest development by creating an account on GitHub.
github.com
참고 자료 : https://inpa.tistory.com/entry/%F0%9F%91%A9%E2%80%8D%F0%9F%92%BB-Is-more-threads-always-better
'스프링' 카테고리의 다른 글
| Apple 로그인 Oauth 2.0 구현 (0) | 2023.10.27 |
|---|---|
| [KaKaoLogin RestAPI] oAuth2.0 + SpringBoot - (1) (0) | 2022.08.19 |
| [Spring Security] + [JWT] + [RefreshToken] 스프링 시큐리티 JWT 로그인 적용기 (0) | 2022.08.18 |
| [Spring Security] + [JWT] 스프링 시큐리티 JWT 로그인[실습] (0) | 2022.08.12 |
| [Spring Security] + [JWT] 스프링 시큐리티 JWT 로그인[이론] (1) | 2022.08.12 |



